在这个故事中,我们将探索如何编写一个简单的基于web的聊天应用程序 Python using LangChain, ChromaDB, ChatGPT 3.5 and Streamlit.
The chat-based app will have its own knowledge base, i.e. it will have its own context. The context will be about Onepoint Consulting Ltd, the company the author of this blog is working for.
The chat app will allow users to query information about Onepoint Consulting Ltd. Here are a few examples of interactions with the chat app:
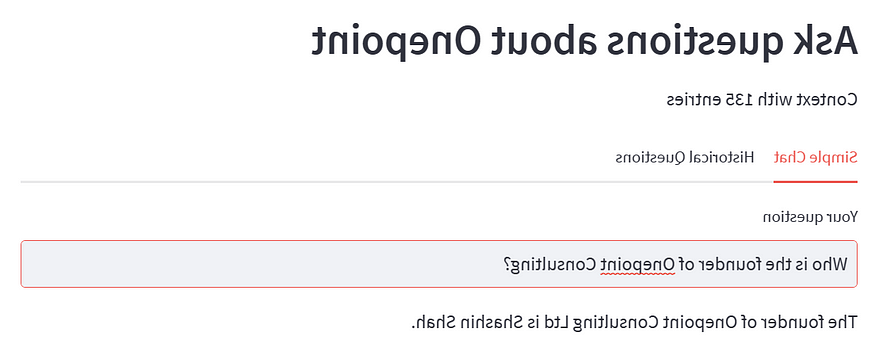

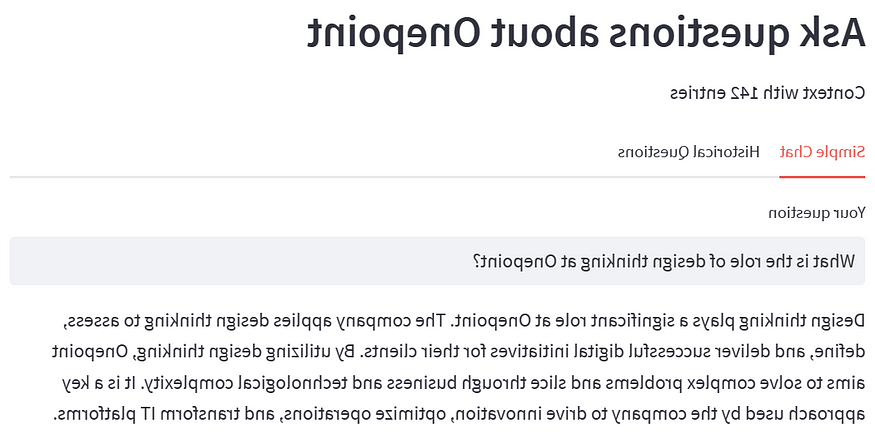
本博客中描述的技术允许您创建基于上下文的聊天应用程序,讨论您选择的任何主题.
Chat App Components
基于上下文的聊天应用程序内部有两个主要组件:
向量数据库是一种较新的数据库类型,它使用向量(数字列表)来表示数据,并且非常适合相似度搜索. This is how Microsoft knowledge base defines what a vector database is:
“矢量数据库是一种将数据存储为高维矢量的数据库, 哪些是特征或属性的数学表示. Each vector has a certain number of dimensions, which can range from tens to thousands, depending on the complexity and granularity of the data.”
使用大语言模型(LLM)处理由向量数据库生成的上下文问题.
Chat App Workflows
The chat app has two workflows:
- Vector DB Creation
- Chat Workflow
矢量数据库创建工作流可以表示为BPMN:
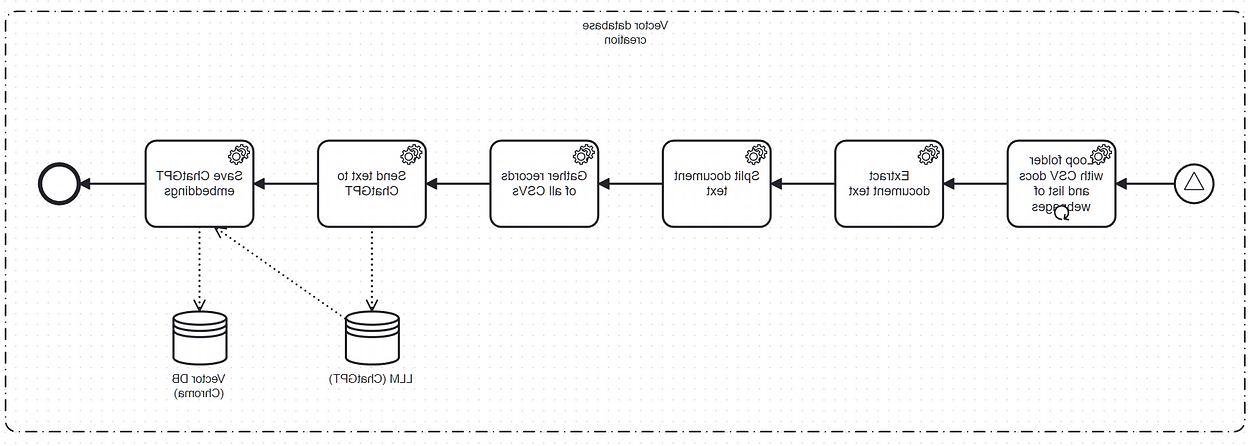
This Vector DB Creation 描述在后台启动聊天应用程序时发生的情况. 此工作流的目标是生成ChatGPT嵌入 ChromaDB.
It performs the following steps:
- 收集指定文件夹下的CSV文件和部分网页
- Extract the text of each CSV file
- Create a list of text records for the CSV file
- Gather all records of all CSV files in a list
- 将收集到的文本列表发送到ChatGPT以收集相应的嵌入
- 使用ChromaDB将ChatGPT嵌入保存在内存中,最终保存在磁盘上.

聊天工作流描述了当用户在用户界面上提出问题时会发生什么:
- The user writes a question and hits the “Enter” button.
- 对向量数据库触发一个相似度搜索查询.
- 对矢量数据库的查询返回特定数量的记录(与问题最相似的记录)
- 这些记录与问题一起发送给法学硕士.
- 然后,LLM回复用户,并在UI上显示响应.
Pre-requisites
We create a Anaconda environment with Python 10 using the following libraries:
langchain==0.0.215
python-dotenv==1.0.0
streamlit==1.23.1
openai==0.27.8
chromadb==0.3.26
tiktoken==0.4.0Implementation
The implementation of the chat engine can be found in:
GitHub - gilfernandes/onepoint_chat:基于点链的迷你聊天应用程序
Onepoint Langchain Based Mini Chat App. 通过创建一个帐户为gilfernandes/onepoint_chat的开发做出贡献…
There is a single file with the whole code:
onepoint_chat/chat_main.py at main · gilfernandes/onepoint_chat
Onepoint Langchain Based Mini Chat App. 通过创建一个帐户为gilfernandes/onepoint_chat的开发做出贡献…
The application starts off with a main method. It executes three steps:
- loads all texts from a specific folder and specific pages
- creates the vector database
- initializes the user interface
def main(doc_location: str ='onepoint_chat'):
"""
Main entry point for the application.
它从特定文件夹和特定网页加载所有文本,
创建矢量数据库并初始化用户界面.
:param doc_location: The location of the CSV files
"""
logger.info(f"Using doc location {doc_location}.")
texts, doc_path = load_texts(doc_location=doc_location)
website_texts = load_website_texts([
'http://www.onepointltd.com/',
'http://www.onepointltd.com/do-data-better/'
])
texts.extend(website_texts)
docsearch = extract_embeddings(text =text, doc_path=Path(doc_path))
init_streamlit(docsearch=docsearch, texts=texts)The method load_texts 加载CSV文件的文本,并将所有文本连接到一个文档对象列表中.
def load_texts(doc_location: str) -> Tuple[List[str], Path]:
"""
加载CSV文件的文本,并将所有文本连接到一个列表中.
:param doc_location: The document location.
:return: a tuple with a list of strings and a path.
"""
doc_path = Path(doc_location)
texts = []
for p in doc_path.glob("*.csv"):
texts.extend(load_csv(p))
logger.info(f"Length of texts: {len(texts)}")
return texts, doc_pathThe method load_csv 使用LangChain的CSV加载器将CSV内容加载为文档列表.
def load_csv(file_path: Path) -> List[Document]:
"""
使用csv加载器将csv内容加载为文档列表.
:param file_path: A CSV file path
:返回:提取并拆分所有CSV记录后的文档列表.
"""
loader = CSVLoader(file_path=str(file_path), encoding="utf-8")
doc_list: List[Document] = loader.load()
doc_list = [d for d in doc_list if d.page_content != 'Question: \nAnswer: ']
logger.info(f"First item: {doc_list[0].page_content}")
logger.info(f"Length of CSV list: {len(doc_list)}")
return split_docs(doc_list)There is also a load_website_texts method to load text from web pages:
def load_website_texts(url_list: List[str]) -> List[Document]:
"""
Used to load website texts.
:param url_list: The list with URLs
:return: a list of documents
"""
documents: List[Document] = []
for url in url_list:
text = text_from_html(requests.get(url).text)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100, separator=".")
texts = text_splitter.split_text(text)
for t in texts:
documents.append(Document(page_content=t))
return documents我们有来自CSV和HTML网站的所有文本,我们现在用下面的方法提取嵌入:
def extract_embeddings(texts: List[Document], doc_path: Path) -> Chroma:
"""
要么将Chroma嵌入保存在本地,要么从磁盘(如果存在的话)读取它们.
:return a Chroma wrapper around the embeddings.
"""
embedding_dir = f"{cfg.chroma_persist_directory}/{doc_path.stem}"
if Path(embedding_dir).exists():
shutil.rmtree(embedding_dir, ignore_errors=True)
try:
docsearch = Chroma.from_documents(texts, cfg.embeddings, persist_directory=embedding_dir)
docsearch.persist()
except Exception as e:
logger.error(f"Failed to process {doc_path}: {str(e)}")
return None
return docsearchFinally, we initialize the Streamlit environment in the init_streamlitfunction. 这段代码需要某种形式的用户问题,然后处理问题. 它还可以处理带有预定义问题的下拉列表中的问题.
def init_streamlit(docsearch: Chroma, texts):
"""
Creates the Streamlit user interface.
这段代码期待某种形式的用户问题,一旦有了它就会处理
the question.
它还可以处理带有预定义问题的下拉列表中的问题.
Use streamlit like this:
streamlit run ./chat_main.py
"""
title = "Ask questions about Onepoint"
st.set_page_config(page_title=title)
st.header(title)
st.write(f"Context with {len(texts)} entries")
simple_chat_tab, historical_tab = st.tabs(["Simple Chat", "Historical Questions"])
with simple_chat_tab:
user_question = st.text_input("Your question")
with st.spinner('Please wait ...'):
process_user_question (docsearch = docsearch user_question = user_question)
with historical_tab:
user_question_2 = st.selectbox("Ask a previous question", read_history())
with st.spinner('Please wait ...'):
logger.info(f"question: {user_question_2}")
process_user_question (docsearch = docsearch user_question = user_question_2)Finally, we have the process_user_question function which performs a search in the vector database, creates a question context, 是和问题一起发给法学硕士的吗.
(docsearch: Chroma, user_question: str):
"""
接收用户问题并在向量数据库中搜索相似的文本文档.
使用相似的文本和用户问题从LLM检索响应.
:param docsearch: The reference to the vector database object
:param user_question: The question the user has typed.
"""
if user_question:
similar_docs: List[Document] = docsearch.similarity_search(user_question, k = 5)
响应,similar_texts = process_question(similar_docs, user_question)
st.markdown(response)
if len(similar_texts) > 0:
write_history(user_question)
st.text("Similar entries (Vector database results)")
st.write(similar_texts)
else:
st.warning("This answer is unrelated to our context.")源代码中还有更多的函数,但是,它们只是简单的辅助函数.
Conclusion
The chat app we built is really very basic in terms of UI. 更好的UI可以用UI Javascript框架编写,比如 Next.Js or Nuxt. Ideally, 您可以通过围绕聊天功能构建REST接口来分离服务器端和客户端.
如果你有一个矢量数据库,创建基于任何知识领域的智能聊天应用程序现在都很容易, an LLM and a UI library like Streamlit. 这是一个非常强大的工具组合,可以真正释放你作为开发人员的创造力.